
![]()
![]()
![]()
![]()

Built by the sole EU-based AI hardware manufacturer. Keep all data, models, and inference in-house or within your sovereign cloud. Full GDPR, HIPAA, and data residency compliance.
Start with Core (inference + model management) and upgrade to Pro (fine-tuning + MLOps) as your AI maturity grows. Pay only for what you need.
Infrastructure as Code scripts deploy the platform in minutes. No months-long integration projects. Certified delivery teams available for complex environments.
Runs on BullSequana servers or your existing GPU infrastructure. No hardware lock-in. Bring your own servers, bring your own GPUs.
Not just GenAI. Combine LLM serving with classical ML, computer vision, document AI, and anomaly detection in unified pipelines. One platform for all AI workloads.
Full L3 support, guaranteed SLAs, 24/7 on-call option, and continuous software updates. Built for production, not prototypes.
![]()
From hardware to virtualization platform, ensuring sovereignty, compliance, and full auditability through open-source engineering.
![]()
Robust and future-proof virtualization solution delivering 60–80% lower TCO compared to traditional options.
![]()
Flexible configurations with BullSequana SH or BullSequana SA to meet diverse workload needs.
![]()
Lightweight hypervisor and optimized design for maximum VM-to-core ratio.
![]()
Full supply chain transparency, advanced hardware protection, and trusted execution technologies.
![]()
Reduced power consumption per workload with eco-conscious infrastructure design and smart VM scheduling.
![]()
Modular, composable hardware with API-driven orchestration for seamless scalability.
![]()
An already validated reference architecture and a SPOC for hardware-software integration and support.
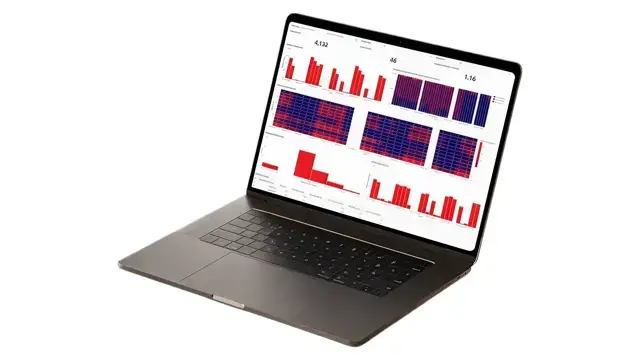
Communication Inspector
Audit 100% of client calls, chats, and emails with LLM-driven compliance analysis.
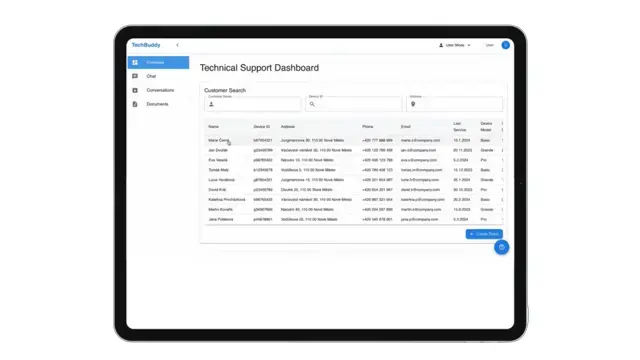
TechBuddy
AI-powered technical assistant for manufacturing and service teams, using RAG on manuals, tickets, and SOPs.

ClaimSense
AI-native claims processing platform achieving 10× faster resolution for insurance teams.

Public healthcare agency
85% accuracy in fraud detection across billions of documents using hybrid classical-ML and GenAI pipelines on the platform.

Enterprise service desk
20% reduction in query processing time, helping users find relevant solutions and procedures faster with AI-assisted search.

Global enterprise clients
Trusted by organisations including L'Oréal, AXA, and government agencies implementing national AI strategies. Delivered by a team of 250+ certified enterprise AI experts.